
Последние несколько лет все больше и больше владельцев веб-сайтов и веб-мастеров сталкиваются со сложностями индексации сайта в поиске Google. Об этом свидетельствуют мои наблюдения за регулярно задаваемыми вопросами об индексировании в Центре Поиска (форум для веб-мастеров), где я имею честь быть экспертом. Разберем подробно какие проблемы могут привести к плохой индексации, делая процесс продвижения сайта еще более сложным..
Содержание:
Что такое индексация сайта в поисковой системе
Очень часто я встречаю, что веб-мастера и владельцы сайтов под индексацией подразумевают весь путь веб-страницы от момента ее появления на ресурсе до показов в выдаче SERP. Однако, на мой взгляд, это не совсем правильно и надо отделять котлеты от мух.
На этом пути есть еще очень важные этапы, следующие друг за другом и заслуживающие отдельного внимания. А в целом весь этот процесс состоит из трех этапов:
- Сканирование,
- Индексация (индексирование),
- Ранжирование.
Индексация — процесс включения информации о просканированной веб-странице или ее фрагменте в базу данных поисковой системы. Кроме того Google способен индексировать большинство текстовых, графических и видео файлов.
Почему стала важна такая конкретизация понятия индексации? Потому что, на моей памяти уже пару лет как, стало отдельным видом квеста в игре под названием seo-оптимизация сайта – добавить все страницы в индекс. Связано это с тремя основными причинами:
- Экономия ресурсов поисковика на краулинг, обработку и хранение данных;
- Исключение из индекса малополезного и дублирующегося контента;
- Борьба со спамом во многих видах его проявления.
Потуги в этом направлении наблюдались и ранее, но появление и сверхбыстрое развитие искусственного интеллекта и использование его в качестве инструмента для массового создания спама. Поэтому, на мой взгляд, было принято вполне логичное решение о дополнительной фильтрации страниц сразу после сканирования до индексации.

Схема индексации веб-страницы. Изображения: flaticon.com
Как проверить индексацию сайта в Google
Способ 1.
Для проверки наличия в индексе сайта целиком или конкретного URL можно воспользоваться встроенным в поиск оператором «site:». Синтаксис оператора выглядит следующим образом:
| Варианты использования оператора site: | |
| site:yoursite.com | Будут показаны результаты для сайта yoursite.com, включая все префиксы и поддомены. |
| site:https://www.yoursite.com/ | Будут показаны результаты для сайта https://www.yoursite.com. Важно, что существует точное соответствие при использовании префикса в операторе site:, то есть site:https://www.yoursite.com/ и site:https://yoursite.com/ это разные запросы и результаты по ним будут отличаться. |
| site:yoursite.com iphone | Покажет список страниц, которые содержат эту фразу или слово, соответственно по этим фразам или словам страница может ранжироваться. |
Оператор необходимо вводить непосредственно в строку поиска Google и нажать Enter или значек лупы. Количество найденных результатов можно увидеть нажав на кнопку «Инструменты».
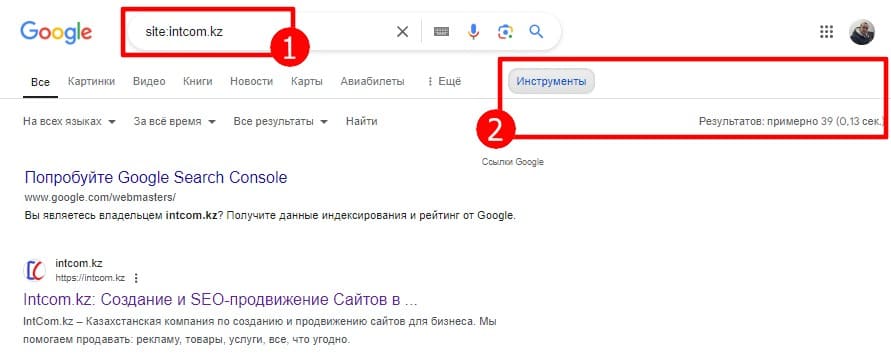
Стоит отметить, что оператор site: не способен выдавать точное количество проиндексированных страниц. Особенно это выражено на крупных сайтах с большим количеством URL. Поэтому показывается примерное количество страниц в индексе. Для более точной и полной картины о состоянии индексации сайта лучше получать следующим способом.
Способ 2.
Если вы хотите получать более достоверную и относительно актуальную информацию об индексации вашего сайта в поиске Google, то без использования такого инструмента как Search Console вам не обойтись. Он довольно удобен в использовании, правда в некоторых местах сложен для понимания ;-).
Подробно рассматривать как добавить сайт в Google Search Console я сейчас рассматривать не буду. Условимся, что сайт у вас туда уже добавлен.
Если вам необходимо проверить индексацию одного конкретного URL необходимо воспользоваться инструментом проверки URL. находится он в верхней части в виде строки поиска. Необходимо вставить туда нужный адрес и нажать Enter.

Будет запущен процесс проверки адреса страницы, по результатам которой будут показаны данные о состоянии в индексе Google: «URL есть в индексе Google» или «URL нет в индексе Google».
В случае, если страница отсутствует в базе данных поиска, можно отправить запрос на индексацию кнопкой «Запросить индексирование».
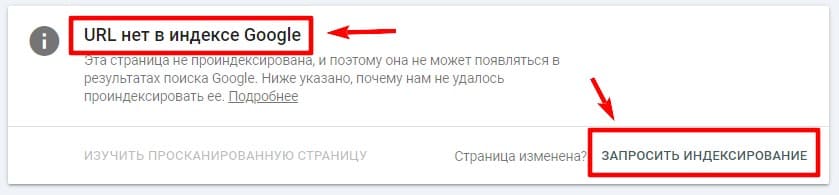
Это действие еще называется «ручная отправка на индексацию». В сутки с одного аккаунта можно отправлять не более 10 таких запросов.
Статус индексации сайта в целом можно просматривать в разделе Индексирование cтраниц. Сюда сводится информация по всем обнаруженным веб-страницам и файлам на вашем ресурсе. В отчете приводится статистика как по успешно пройденным, так и по найденным ошибкам, мешающим индексированию.
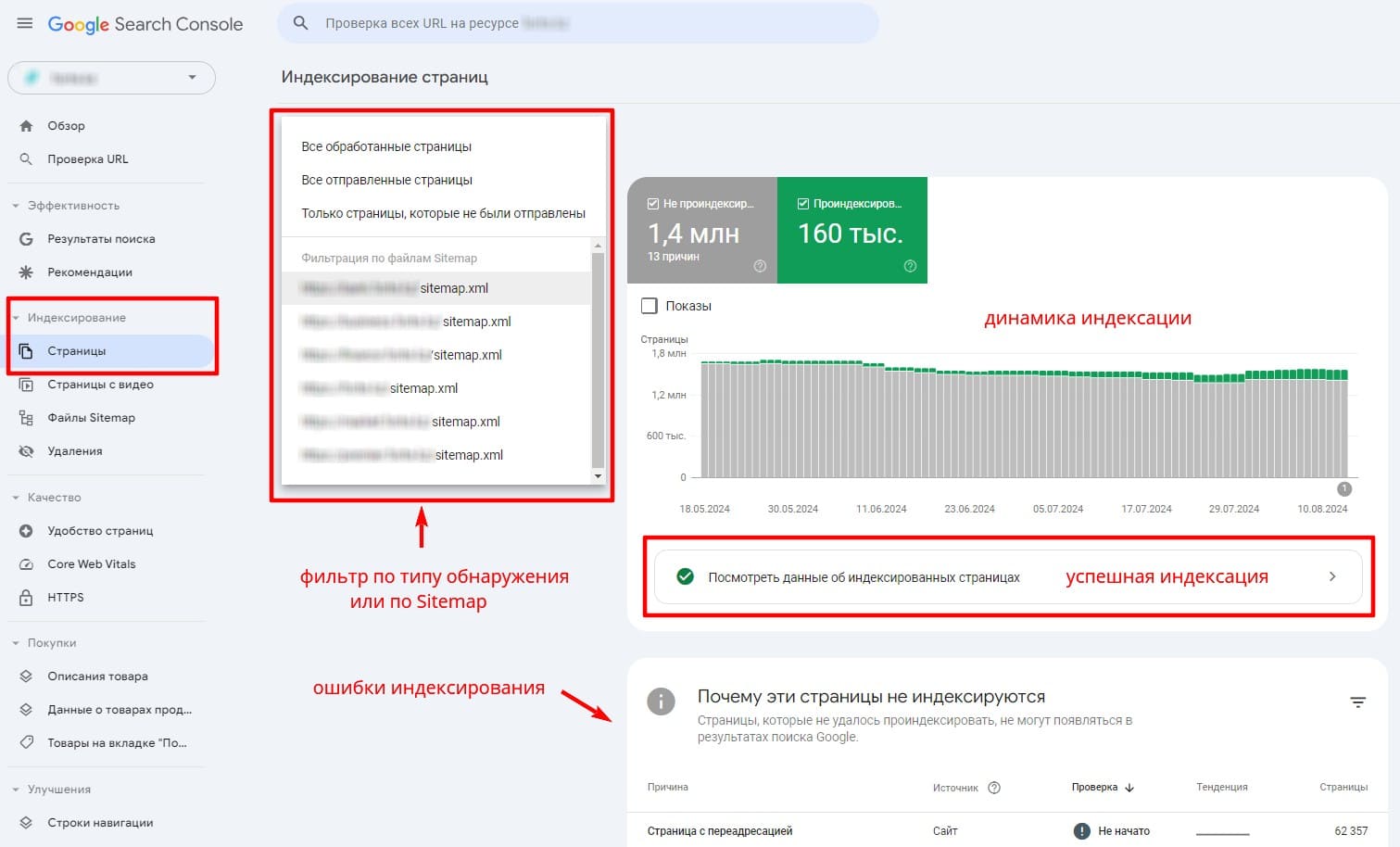
Отчет Индексирование страниц в Search Console
Почему мой сайт не индексируется в Google
Сложности с индексацией сайта в поиске Google могут возникнуть у любого веб-ресурса. Вне зависимости от тематики и возраста сайта.
По личным наблюдениям за своими проектами и сообщениям веб-мастеров на форуме Центр Поиска я разделяю проблемы индексации на:
- Технические;
- Алгоритмические.
Технические проблемы индексации сайта
Наиболее частые трудности в процессе включения в индекс поисковой системы возникают именно на этапе сканирования. Ведь без нормальных технических условий для сканирования со стороны сайта об успешном индексировании говорить не приходится. Рассмотрим наиболее частые ошибки.
Блокировка сканирования в файле robots.txt
Иногда становится грустно когда вижу рекомендации о возможном управлении процессом индексации в файле robots.txt 🤦♂️. Безусловно, в этом прощупывается некая логика: если бот не смог просканировать, значит не проиндексирует. Однако это работает не совсем так. Дело в том, что следование правилам блокировки в robots.txt носит весьма условно-обязательный характер для краулера и может быть с легкостью проигнорировано.
Например если на страницу, закрытую для сканирования в роботсе, стоят внешние ссылки и алгоритмы определят, что здесь есть контент достойный индексации — проиндексирует несмотря на блокировку.
Или по каким то другим (одному ему ведомым) причинам robots будет попросту игнорироваться, полностью или частично. В результате в SC будет висеть уведомление «Проиндексировано, несмотря на блокировку в файле robots.txt».
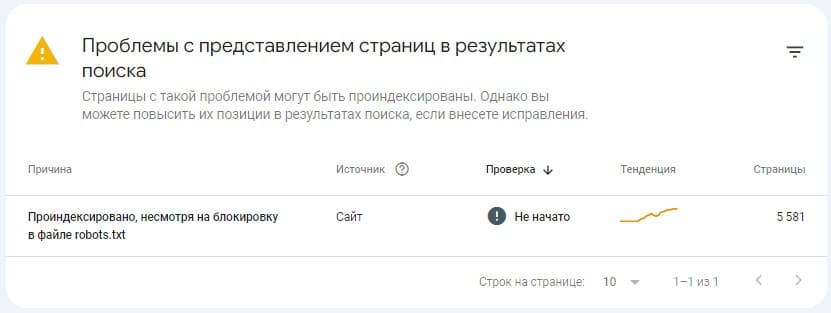
Пример уведомления в Search Console «Проиндексировано, несмотря на блокировку в файле robots txt»
Иногда веб-мастера пытаются ограничивать сканирование не целых страниц, а критически важных ее элементов — CSS и JS файлы. По моим предположениям делается это с целью экономии краулингового бюджета (или просто по неопытности). Из чего получается еще один пример некорректного использования директив Disallow.
При попытке загрузить страницу с заблокированными скриптами и стилями (в этом случае уже будут неукоснительно выполняться требования в robots), бот попросту получит страницу с, мягко говоря, непотребным содержимым. Элементы будут выходить за пределы экрана, разъезжаться кто куда и другие подобного рода несоответствия. Поэтому может быть сделан вывод о низком уровне удобства использования ресурса.
Блокировка или ограничение доступа для поисковых роботов
Помимо краулеров Google существует еще огромное количество ботов, пытающихся просканировать ваш сайт, создавая дополнительную нагрузку на сервер. Желание ограничить доступ таким «вредным» путем установки различного рода файрволов или блокировщиков доступа вполне оправдано и может помочь избавиться (хотя бы частично) от спама или парсинга контента.
Иногда так случается, что попутно на уровне сервера или сервиса (Cloudflare и ему подобные) закрывается доступ для абсолютно всех ботов-сканеров. Поэтому не лишним будет проверить в настройках ограничения на доступ ботов добавлен ли краулер гугл в исключения.
Проверить доступность можно при помощи Инструмента проверки URL в Search Console.
Стабильная работа хостинга и количество ресурсов
Выбор хостинг-провайдера казалось бы довольно простая задача и следует выбирать наиболее стабильно работающего поставщика услуг. Это необходимо для обеспечения доступности ресурса в любой момент времени и без задержек, потому что мы не можем управлять расписанием сканирования.
Если при попытке сканирования краулер будет получать ошибки со стороны сервера, то это может быть воспринято негативно. В следствие чего будет снижена квота на сканирование и его частота. В свою очередь это скажется на скорости включения новых страниц в индекс, а также их количестве.
Для анализа доступности сайта можно периодически заглядывать в отчет «Статус хоста».
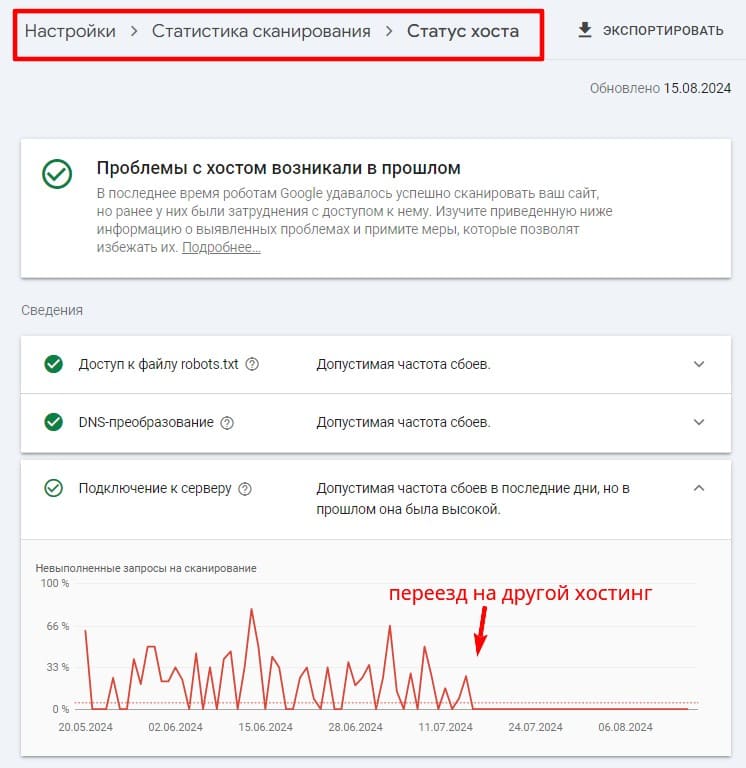
Пример решения проблем с доступностью сайта посредством смены хостера.
Также алгоритмы способны определять не создают ли подключения гугл бота излишней нагрузки на стабильность работы хоста. Если таковые будут обнаружены, частота может быть существенно снижена.
Индексация страниц не адаптированных для мобильных устройств
Уже несколько лет длятся эпопея с переходом на индексирование с приоритетом контента для мобильных устройств. И вот свершилось, 3 июня 2024 Джон Мюллер объявил:
Большинство сайтов в интернете уже сканируется именно так, и для них ничего не изменится. С 5 июля 2024 г. для сканирования и индексирования таких сайтов будет использоваться только робот Googlebot Smartphone. Мы перестанем индексировать сайты, контент которых нельзя посмотреть на мобильном устройстве.
Комментировать тут особо нечего. Делайте сайты для девайсов с маленьким экраном и следите за тем, чтобы боты могли это понимать.
Блокировка индексации директивой noindex
Директива noindex — самый надежный способ исключить показ веб-страницы из поисковой выдачи. Так случается, что по невнимательности или в результате неверной настройки системы управления сайтом она может быть добавлена на полезные и качественные страницы.
При обнаружении ботами такие страницы будут просканированы и добавлены в отчет о сканировании «Индексирование страницы запрещено тегом noindex».
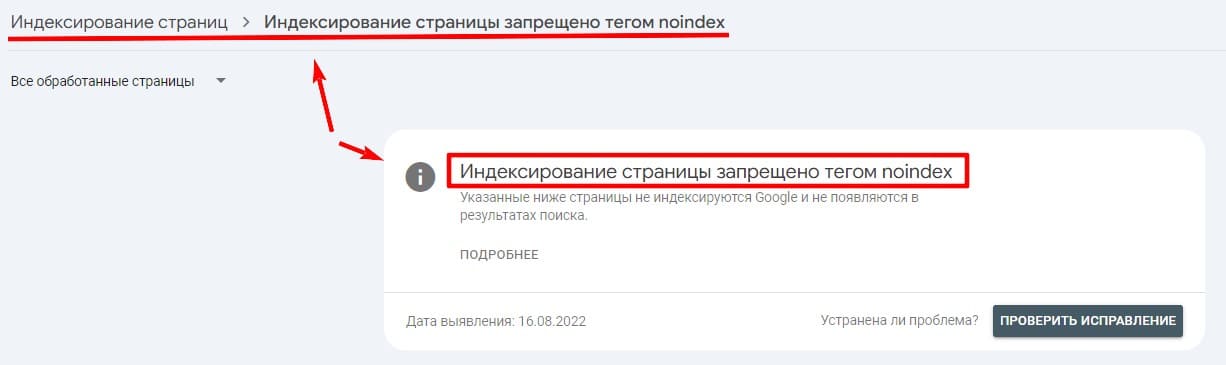
Отчет носит исключительно информационный характер. Если в списке примеров страниц находятся только те, которым специально добавлена директива — значит все в порядке.
Алгоритмические проблемы индексации сайта
Когда вся техническая сторона проблемы проработана и не вызывает вопросов, стоит обратить внимание на алгоритмичесские факторы низкой индексации или частичного (полного) ее отсутсвия. Если с техничкой все боле менее понятно и даже есть документация, то с этой частью возникает больше всего вопросов.
Попытаюсь немного раскрыть суть почему сайт плохо индексируется в Google.
Меры, принятые вручную или нарушения безопасности
На сколько мне известно меры, принятые вручную или, как говорят в народе, «ручник» стало довольно редким явлением. Потому что большую часть проверки нарушений человеком способны делать алгоритмы. И если раньше при проверке сайта человеком и принятии решения об ограничительных мерах вам приходило уведомление в консоль. То теперь большинство таких проверок и пессимизаций происходит на автомате.
Алгоритм не будет информировать владельца сайта о пессимизации, просто понизит позиции (или вообще исключит из выдачи).
Жалобы DMCA
Защита интеллектуальной собственности является вполне естественным желанием любого правообладателя. Поэтому при копировании или незаконном использовании чужого контента (тексты, аудиофайлы, видео, документы и так далее) на вас могут подать жалобу DMCA.
Если жалобы поступают регулярно или от нескольких правообладателей, то о хорошей индексации ресурса и уж тем более ранжировании можно забыть.
Низкокачественный или скопированный контент
Качество контента — один из важнейших факторов успешного продвижения сайта в поиске. А системы обнаружения контента низкого качества, копипасты или откровенного спама постоянно обновляются и совершенствуются. Поэтому однозначно стоит уделять этому особое внимание, ведь, в конечном итоге, это напрямую влияет на индексацию сайта.
При этом важно чтобы качественными были не только отдельные страницы, но и сайт в целом. По моим личным наблюдениям существует некий процентиль отношения хороших страниц к не очень хорошим. И от этого зависит как квота на сканирование, так и шансы на успешную индексацию.
Не лишним будет выдержка на должном уровне и уникальности контента. Перед публикацией как минимум необходимо провериться на плагиат. Потому что алгоритмы довольно хорошо определяют скопированный контент и могут установить в качестве канонического URL, страницу откуда он был скопирован. А неканонические страницы практически никогда не индексируются.
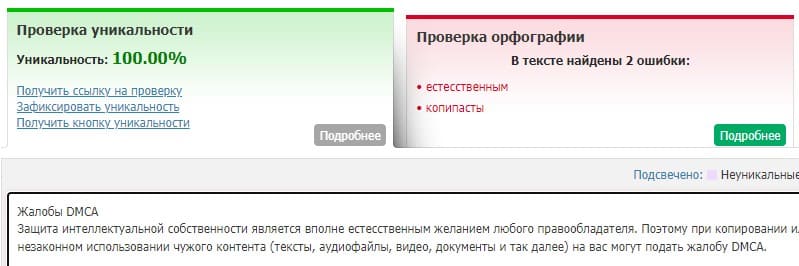
Пример проверки небольшого текста на уникальность.
Вопрос качества довольно широкий и имеет множество нюансов, достойных отдельного освещения. По этой теме сделаю отдельную статью.
Структура сайта и глубина вложенности страниц
Структурирование контента на сайте позволяет легче ориентироваться не только пользователям, но и краулеру. Чем более логична и понятна иерархия страниц, тем выше будет показатель качества сайта в целом. А это бесспорный плюс в карму.
Также замечено, что поисковая машина довольно неохотно берет в индекс страницы, расположенные в глубине сайта. И чем длиннее путь к контенту, тем менее ценным он может быть. И наоборот, чем ближе страница находится к корневой директории, тем выше вероятность ее ценности. Поэтому не стоит увлекаться и создавать слишком большую вложенность, чем проще, тем лучше.
Как улучшить индексацию сайта в поиске
Улучшение процесса индексирования стало весьмо тривиальной задачей, однако для многих людей это по прежнему остается довольно сложной для понимания проблемой. Так происходит потому что SEO становится более сложным и многогранным процессом. А алгоритмы постоянно совершенствуются, появляются новые связи факторов и трактовки показателей. К сожалению (или к счастью) люди не всегда способны быстро к этому адаптироваться, научиться мыслить по новому.
На мой взгляд первое, что необходимос сделать — это научиться смотреть на ситуацию (проблему) с другой точки зрения, критически отнестись к своему подходу и методам. Если ситуация не улучшается, значит пора что то менять. Возможно, стоит обратиться за помощью к стороннему SEO-специалисту за аудитом, который точно не будет заниматься лоялизмом и укажет на все возможные недоработки (ошибки).
Тем не менее, если вы все же хотите самостоятельно докопаться до сути проблемы или просто обязаны сделать это по долгу профессии, необходимо:
- Проверить на все возможные технические проблемы доступности сайта краулеру и устранить их;
- Устранить все проблемы индексации по списку из Search Console (конечно если эти ограничения не сделаны намеренно);
- Оптимизировать структуру сайта, сделать ее более логичной и понятной;
- Создавать полезный и уникальный, ориентированный на людей контент, закрывать интент пользователя;
- Уделять внимание внутренней перелинковке;
- Избегать создания страниц-сирот;
- Промоушен и привлечение трафика с других тематических сайтов (внешнее ссылочное);
- Диверсификация трафика. Использовать максимальное количество точек входа на сайт не концентрироваться только на поиск;
- Развивать бренд и его узнаваемость.
За каждым из этих пунктов стоит огромный объем работы. И не всегда можно осилить его в одиночку. Но, если планируете в долгую работать, то делать его все равно придется.
Если все сделано, на ваш субъективный взгляд, «по учебнику» и все равно не индексирует страницы — можно попробовать отправить информацию о проблеме непосредственно инженерам Google (последняя ссылка в Источниках). Но, если там не выявят технических проблем на стороне вашего сайта или стороне краулера, то, вероятней всего, проблема алгоритмическая и вы не получите никакого ответа.
Заключение (или что то вроде того).
Особо нечего тут заключать. Наливаем свежий кофе, протираем окуляры, рукава закатываем повыше и вперед работать!
